Interplanetary Linked Data (IPLD) is a data format for merkle-linked objects. Its purpose is to make it easy to build your own hash linked data structures and move them around with IPFS. IPLD objects are stored and moved around by IPFS encoded with CBOR, but can be written and operated on in JSON or any other schemaless serialization format.
When an object is added to the IPFS it is chunked up into smaller parts (about 256k each), each part is hashed, a CID is created for each chunk, and then these chunks are combined into a hierarchical data structure, for which a single, base CID is computed. This data structure is essentially something called a Merkle DAG, or directed acyclic graph.
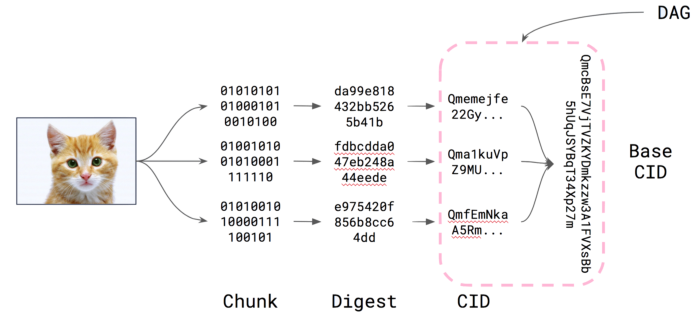
In the example above, a cat photo added to the ipfs is hashed and added into the Merkle DAG. These Merkle DAGs are the core data structure for the IPLD structure.
Hash-Linked Data Structures
IPLD is a hash-linked data structure that models everything as a series of linked objects.
An IPLD oject consists of:
- Data — blob of unstructured binary data of size 256 kB.
- Links — array of Link structures. These are links to other IPFS objects.
A Link structure has three data fields:
- Name — name of the Link
- Hash — hash of the linked IPFS object
- Size — cumulative size of linked IPFS object, including following its links
An IPLD object looks something like this:
{
"hello": "world",
"foo": {"/": "QmTz3oc4gdpRMKP2sdGUPZTAGRngqjsi99BPoztyP53JMM"},
"baz": [
{"/": "QmWg1Ux3cb3xCToGBCmZBNaMvpcFhTEEjb74fruG9uVHja"}
]
}
The basic idea is that any valid CBOR object (and subsequently, any valid JSON object since they map 1-to-1) can be an IPLD object. On top of that, theres a special format for inserting merkle-links that is the real meat of IPLD. The strange objects with a key of '/' and a value of an IPFS hash are the links. These links are understood by IPFS and can be used to build path references across objects.
IPLD: Getting Started
To truly apprecite IPLD, we are going to learn the basics using simple IPFS command line tools. Initial IPLD support has been released in ipfs, install or update IPFS before following along on the rest of this guide. Once you’re ready, we’ll take a quick look at the object structure for a simple hello.txt file using the jq tool.
Start with the following command, which pipes (|) the result from getting the IPFS object to the jq command.
ipfs object get QmJTB2qXtFCfLarActp7tDNikE4PdsgaTQW2WQi7j6c7Ug | jq
Producing the following output:
{
"Links": [
{
"Name": "hello.txt",
"Hash": "Qm34sdwMe9USZ7nS1YhWrCiS4gz7Xiud286K6pohQcTKYq",
"Size": 181100
}
],
"Data": "\b\u0001"
}
This is pretty cool, but let’s say you had the following directory structure, and you wanted to add it to IPFS:
test_directory/
├── bigfile.js
├── *hello.txt
└── my_directory
├── *test_file.txt
└── *test.txt
Here, we assume that all three files with an asterisk (*) — hello.txt, test_file.txt, and test.txt— contain the same text: “Hello World!/n”. Now let’s add them to IPFS:
ipfs add -r test_directory/
The newly created DAG for your upload will look similar to this:
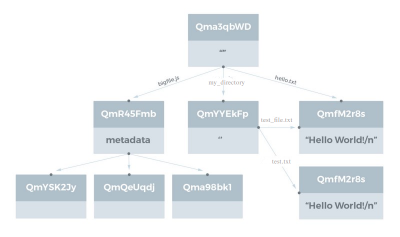
As illustrated above, the benefits of using a DAG to represent data in IPFS is very clear, depending on the actual contents of the files in your directory, you end up with a series of objects, linked via their CIDs. This is pretty cool and since we are referencing the same content we get deduplication for free!
Important to note our bigfile.js, been chunked into three smaller pieces, each of which has its own CID, which together form the larger file. Following all of these CIDs up the tree, will give you a CID that describes the contents below it. This is the genius of IPLD.
This collection of Data and Links across the IPFS network creates a graph-like object structure - commonly referred to as the merkle forest by Juan Benet. This data structure is highly tamper proof, because all content its `hash-verified` And since we are hashing the contents of the objects, we have no duplication, because in the Merkle DAG, all objects that hold the same content are considered equal and therefore stored only once because their hash values are the same.
We can demonstrate this further by using Matt Zumwalt's building out files-as-dags lesson tutorial. We will `ipfs cat` the cosmos.jpg file from the command line:
ipfs cat QmWNj1pTSjbauDHpdyg5HQ26vYcNWnubg1JehmwAE9NnU9 > cosmos.jpg
Now you can add it locally, and if you cat’d it initially, make sure the hashes match then assign the returned hash to the env variable hash:
hash=`ipfs add -q cosmos.jpg`| echo $hash
The CID output should match the image hash like this:
QmWNj1pTSjbauDHpdyg5HQ26vYcNWnubg1JehmwAE9NnU9
Now, that the file has been chunked we can query all the ipfs objects for the image by running:
ipfs ls -v $hash
Each linked object is about 256k, together these chunks make up the whole image - and when a network request for this file is made, different peers share a different chunk of the image which is put together by the requesting peer.
Hash Size Name
QmPHPs1P3JaWi53q5qqiNauPhiTqa3S1mbszcVPHKGNWRh 262158
QmPCuqUTNb21VDqtp5b8VsNzKEMtUsZCCVsEUBrjhERRSR 262158
QmS7zrNSHEt5GpcaKrwdbnv1nckBreUxWnLaV4qivjaNr3 262158
QmQQhY1syuqo9Sq6wLFAupHBEeqfB8jNnzYUSgZGARJrYa 76151
You can also use this super new and fun tool to explore DAGs (IPLD obejcts) in the browser. Check out the git example for a fun one. Or even better, explore the above DAG object.
Now, just to show you that the above four chunks do indeed make up the single image, you can use the following code to manually join the chunks together to create the image file — which is essentially what cat is doing in the background when you reference the base CID:
ipfs cat \
QmPHPs1P3JaWi53q5qqiNauPhiTqa3S1mbszcVPHKGNWRh \
QmPCuqUTNb21VDqtp5b8VsNzKEMtUsZCCVsEUBrjhERRSR \
QmS7zrNSHEt5GpcaKrwdbnv1nckBreUxWnLaV4qivjaNr3 \
QmQQhY1syuqo9Sq6wLFAupHBEeqfB8jNnzYUSgZGARJrYa \
> cat-cosmos.jpg
open cat-cosmos.jpg
Alternatively, you could do this more succinctly using pipes again:
ipfs refs $hash | ipfs cat > test.jpg ; open test.jpg
There you go. It’s links all the way down. And on top of that we’ve learned a few many IPFS command-line tools to manipulate IPFS DAG objects. Handy!
Summary
The IPLD protocol is magic that runs on cryptography, math and networking. Its a single namespace for all hash-inspired protocols. Through IPLD, links can be traversed across protocols, allowing you explore data regardless of the underlying protocol. We can use it to referencea large data files using only the base CID, and you actually have a verified reference to the whole object. With the simple ipfs add command a new merkle DAG is created from data in the files, this command also creates the underlying IPNS objects you'll need to access your files.
With such great technology, there's nothing stopping you from building great distributed web projects. If you're already work on one, I'd love to hear about it!